In the present world, technologies are updating day by day with plenty of advanced facilities. Likewise, the installation of InfluxDB on windows tutorials also may differ some time to time. So, here we have come up with a useful and handy tutorial on How To Install InfluxDB on Windows which is good and up-to-date among others.
These types of technologies may change and grow all the time so educational resources should adapt properly. The main objective of offering this tutorial is to have an insightful and up-to-date article on how to install it on Windows.
The tutorial of Install InfluxDB on Windows in 2021 covers the following stuff in a detailed way:
- How do you install InfluxDB on Windows in 2021?
- How to download InfluxDB on Windows
- How to configure InfluxDB on your machine
- How to Run InfluxDB as a Windows service using NSSM Tool?
- Most Common Mistakes In The Process
Be ready to follow all the required steps for a clean InfluxDB installation.
How do you install InfluxDB on Windows in 2021?
Check out this video tutorial on how to install InfluxDB on windows and moreover, you can learn the basic commands of influxdb, and integration with Grafana from here:
How to download InfluxDB on Windows?
By following the below two methods, you can easily download the InfluxDB on windows:
a – Downloading the archive
Downloading InfluxDB is very straightforward.
Head over to the InfluxDB downloads page. There, you will see the following four boxes.

What are those four boxes for?
They are part of the TICK stack. (Telegraf, InfluxDB, Chronograf, and Kapacitor).
Each of these tools has a very specific role: gathering metrics, storing data, visualizing time series or having post-processing defined functions on your data.
In this tutorial, we are going to focus on InfluxDB (the time series database component of TICK)
- How To Install InfluxDB 1.7 and 2.0 on Linux in 2021
- How To Install InfluxDB Telegraf and Grafana on Docker
- How To Create a Database on InfluxDB 1.7 & 2.0
So should you download the v1.7.6 or v2.0.0 version?
In my previous articles, I answered the main difference between the two versions, but here’s the main difference you need to remember.
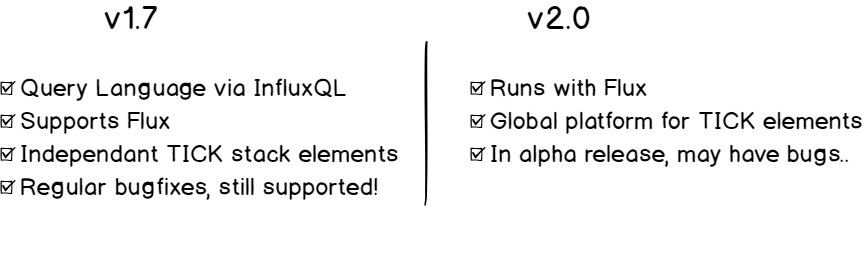
As the 2.0 version is still experimental, we are going to go for the 1.7.6 version.
Click on the v1.7.6 button.
Another window will open with all operating systems. Scroll until you see Windows Binaries (64-bit).

Simply click on the URL in the white box, and the download will automatically start in your browser.
Store it wherever you want, in my case, it will be in the Program Files folder.
Unzip the archive using your favorite archive utility tool (7-Zip in my case) or run the following command in a Powershell command line.
Expand-Archive -Force C:\path\to\archive.zip C:\where\to\extract\toGreat! Let’s take a look at what you have here.
b – Inspecting the archive
Inside your folder, you now have 5 binaries and 1 configuration file:
- influx.exe: a CLI used to execute IFQL commands and navigate into your databases.
- influx_inspect.exe: get some information about InfluxDB shards (in a multinode environment)
- influx_stress.exe: used to stress-test your InfluxDB database
- influx_tsm.exe: InfluxDB time-structured merge tree utility (not relevant here)
- influxd.exe: used to launch your InfluxDB server
- influxdb.conf: used to configure your InfluxDB instance.
Relevant binaries were marked in bold.
Also Check: How To Create a Grafana Dashboard? (UI + API methods)
How to configure InfluxDB Server on your Machine
Before continuing, you have to configure your InfluxDB instance for Windows.
We are essentially interested in four sections in the configuration file.
a – Meta section
This is where your raft database will be stored. It stores metadata about your InfluxDB instance.
Create a meta folder in your InfluxDB directory (remember in my case it was Program Files).
Modify the following section in the configuration file.
[meta] # Where the metadata/raft database is stored dir = "C:\\Program Files\\InfluxDB\\meta"
b – Data section
InfluxDB stores TSM and WAL files as part of its internal storage. This is where your data is going to be stored on your computer. Create a data and a wal folder in your folder. Again, modify the configuration file accordingly.
[data] # The directory where the TSM storage engine stores TSM files. dir = "C:\\Program Files\\InfluxDB\\data" # The directory where the TSM storage engine stores WAL files. wal-dir = "C:\\Program Files\\InfluxDB\\wal
Important: you need to put double quotes in the path!
c – HTTP section
There are many ways to insert data into an InfluxDB database.
You can use client libraries to use in your Python, Java, or Javascript applications. Or you can use the HTTP endpoint directly.
InfluxDB exposes an endpoint that one can use to interact with the database. It is on port 8086. (here’s the full reference of the HTTP API)
Back to your configuration file. Configure the HTTP section as follows:
[http] # Determines whether HTTP endpoint is enabled. enabled = true # The bind address used by the HTTP service. bind-address = ":8086" # Determines whether HTTP request logging is enabled. log-enabled = true
Feel free to change the port as long as it is not interfering with ports already used on your Windows machine or server.
d – Logging section
The logging section is used to determine which levels of the log will be stored for your InfluxDB server. The parameter by default is “info”, but feel free to change it if you want to be notified only for “error” messages for example.
[logging] # Determines which log encoder to use for logs. Available options # are auto, logfmt, and json. auto will use a more user-friendly # output format if the output terminal is a TTY, but the format is not as # easily machine-readable. When the output is a non-TTY, auto will use # logfmt. # format = "auto" # Determines which level of logs will be emitted. The available levels # are error, warn, info, and debug. Logs that are equal to or above the # specified level will be emitted. level = "error"
e – Quick test
Before configuring InfluxDB as a service, let’s run a quick-dry test to see if everything is okay.
In a command-line, execute the influxd executable. Accept the firewall permission if you are prompted to do it.
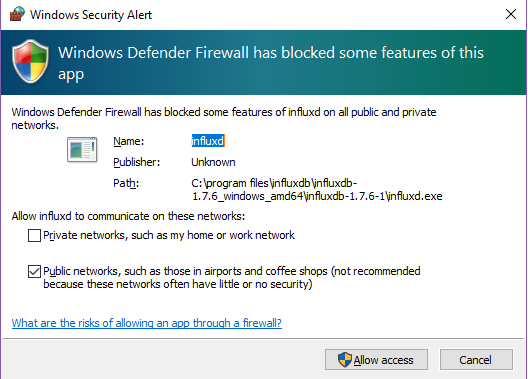
Now that your InfluxDB server has started, start a new command-line utility and run the following command.
C:\Users\Antoine>curl -sl -I http://localhost:8086/ping
HTTP/1.1 204 No Content
Content-Type: application/json
Request-Id: 7dacef6d-8c2f-11e9-8018-d8cb8aa356bb
X-Influxdb-Build: OSS
X-Influxdb-Version: 1.7.6
X-Request-Id: 7dacef6d-8c2f-11e9-8018-d8cb8aa356bb
Date: Tue, 11 Jun 2021 09:58:41 GMTThe /ping endpoint is used to check if your server is running or not.
Are you getting a 204 No Content HTTP response?
Congratulations!
You now simply have to run it as a service, and you will be all done.
How to Run InfluxDB as a Windows service using NSSM Tool?
As you guessed, you are not going to run InfluxDB via the command line every time you want to run it. That’s not very practical.
You are going to run it as a service, using the very popular NSSM tool on Windows.
You could use the SC tool that is natively available on Windows, but I just find it more complicated than NSSM.
To download NSSM, head over to https://nssm.cc/download.
Extract it in the folder that you want, for me, it will be “C:\Program Files\NSSM”.
From there, in the current NSSM folder, run the following command (you need administrative rights to do it)
> nssm install
You will be prompted with the NSSM window.
Enter the following details in it (don’t forget the config section, otherwise our previous work is useless)
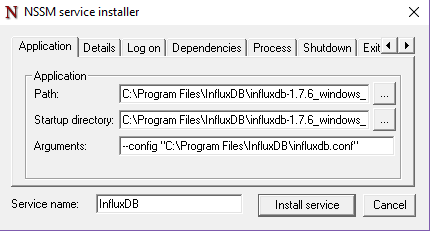
That’s it!
Now your service is installed.
Head over to the services in Windows 10. Find your service under the name and verify that its status is “Running” (if you specified an automatic startup type in NSSM of course)
Is it running? Let’s verify one more time with curl.
C:\Users\Antoine>curl -sL -I http://localhost:8086/ping HTTP/1.1 204 No Content Content-Type: application/json Request-Id: ef473e13-8c38-11e9-8005-d8cb8aa356bb X-Influxdb-Build: OSS X-Influxdb-Version: 1.7.6 X-Request-Id: ef473e13-8c38-11e9-8005-d8cb8aa356bb Date: Tue, 11 Jun 2021 11:06:17 GMT
Congratulations! You did it!
You installed InfluxDB on Windows as a service, and it is running on port 8086.
Most Common Mistakes In The Process
The service did not respond in a timely fashion.
I encountered this error when I tried to set up InfluxDB as a service using SC. As many solutions exist on Google and on Youtube, I solved it by using NSSM.
Tried tweaking the Windows registry but it wasn’t very useful at all.
Only one usage of each socket address (protocol/network address/port) is normally permitted.
Simple, there is already a program or service listening on 8086. You should modify the default port in the configuration file and take one that is permitted and not used.
I don’t have the same curl response
A 204 response to the curl command is the only sign that your InfluxDB is running correctly. If you don’t get the same output, you should go back and double-check the steps before.
I have a parsing error in my configuration file!
Remember that in Windows systems backslashs have to be escaped. It’s double backslashs in the paths of your InfluxDB configuration file.
If your path contains some spaces, like “Program Files”, make sure to put your path into quotes.