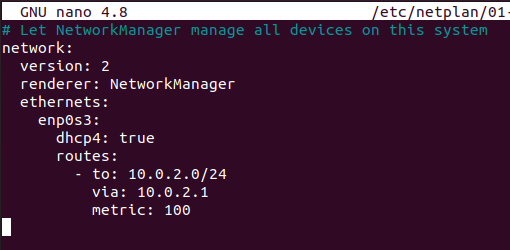
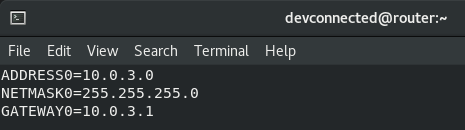
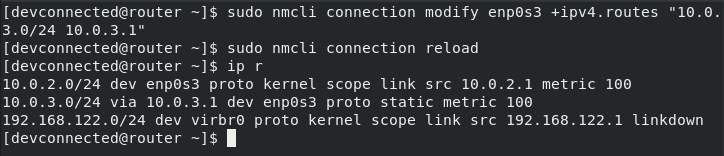
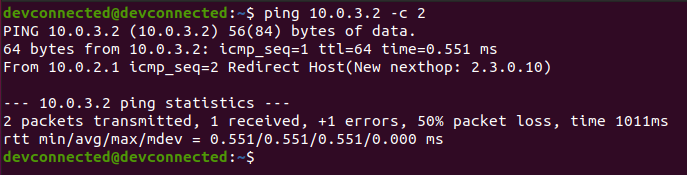
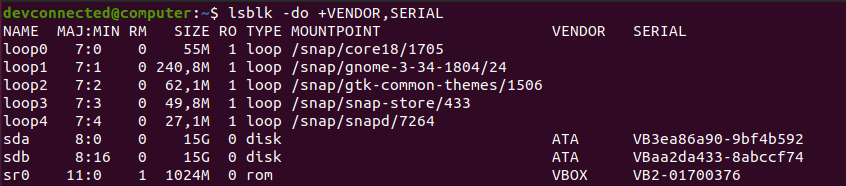
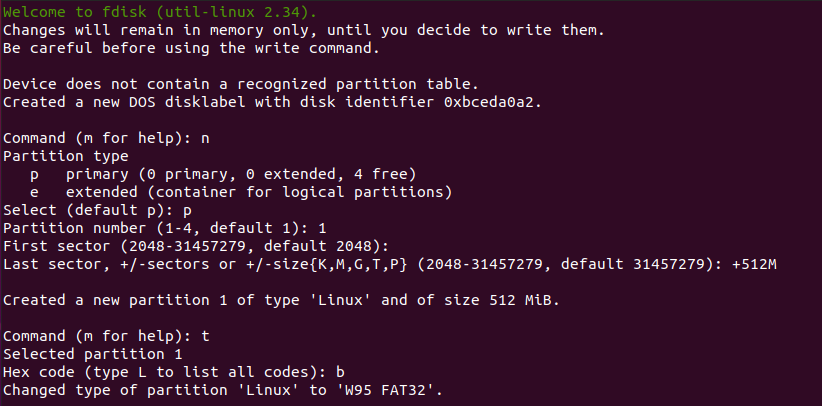
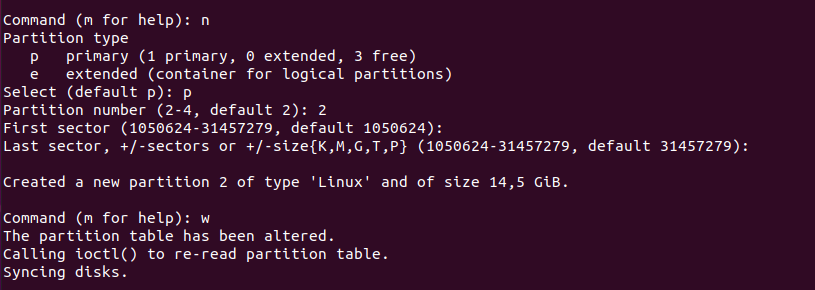
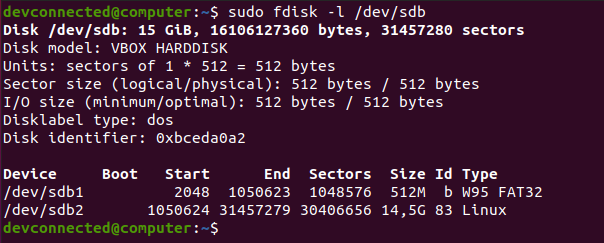
ZIP is by far one of the most popular archive file format among system administrators.
Used in order to save space on Linux filesystems, it can be used in order to zip multiple files on Linux easily.
In this tutorial, we are going to see how can easily zip multiple files on Linux using the zip command.
Prerequisites
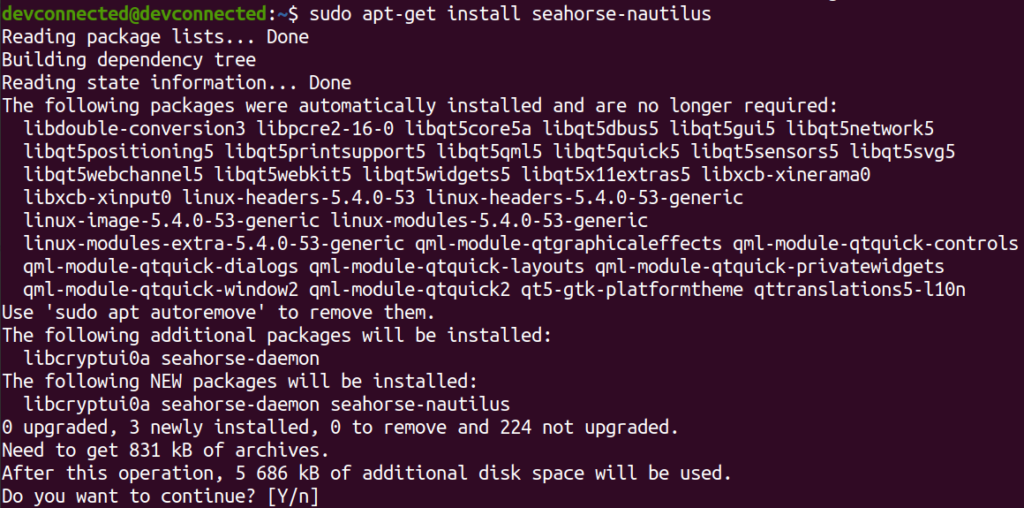
In order to zip multiple files on Linux, you need to have zip installed.
If the zip command is not found on your system, make sure to install it using APT or YUM
$ sudo apt-get install zip $ sudo yum install zip
Zip Multiple Files on Linux
In order to zip multiple files using the zip command, you can simply append all your filenames.
$ zip archive.zip file1 file2 file3 adding: file1 (stored 0%) adding: file2 (stored 0%) adding: file3 (stored 0%)
Alternatively, you can use a wildcard if you are able to group your files by extension.
$ zip archive.zip *.txt adding: file.txt (stored 0%) adding: license.txt (stored 0%) $ zip archive.zip *.iso adding: debian-10.iso (stored 0%) adding: centos-8.iso (stored 0%)
- Learn How to Extract a (Unzip) tar.xz File
- Linux Tee Command with Examples
- How to Rename Files and Directories in Linux
Zip Multiple Directories on Linux
Similarly, you can zip multiple directories by simply appending the directory names to your command.
$ zip archive.zip directory1 directory2 adding: directory1/ (stored 0%) adding: directory2/ (stored 0%)
Conclusion
In this tutorial, you learnt how you can easily zip multiple files on Linux using the zip command.
You also learnt that wildcards can be used and that you can zip multiple directories similarly.
If you are interested in Linux System Administration, we have a complete section dedicated to it on the website, so make sure to have a look.