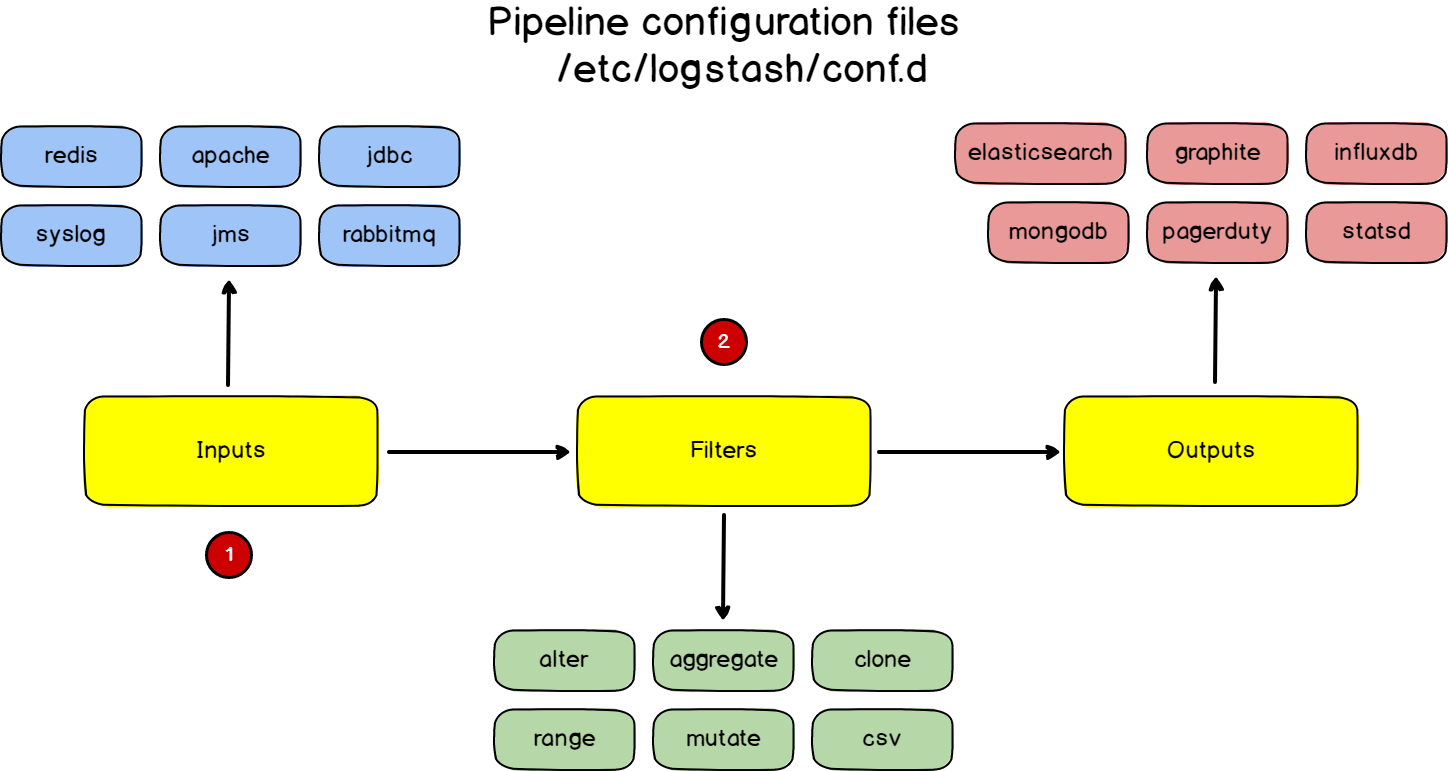
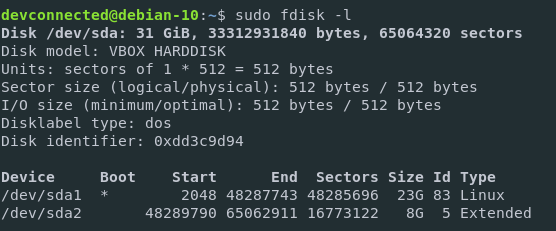
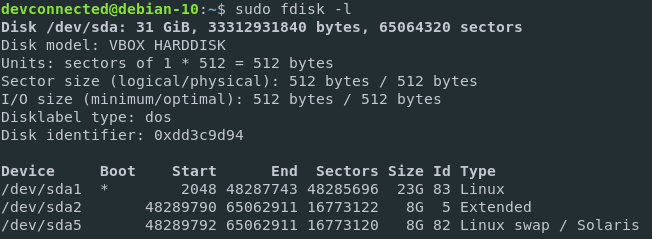
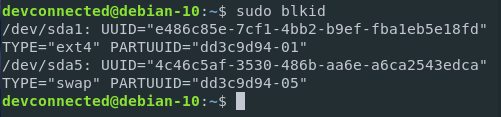
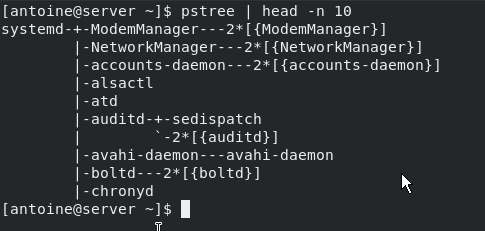
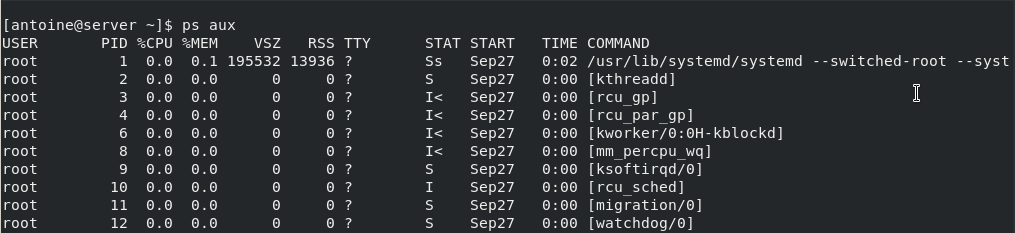
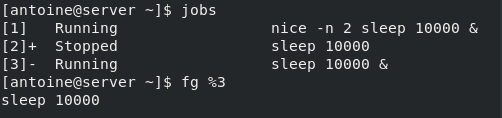
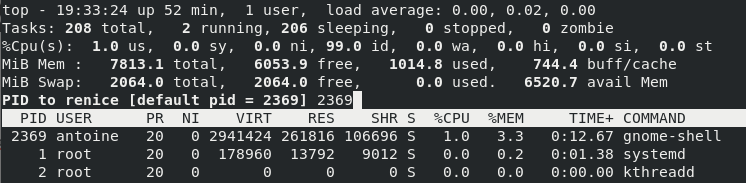
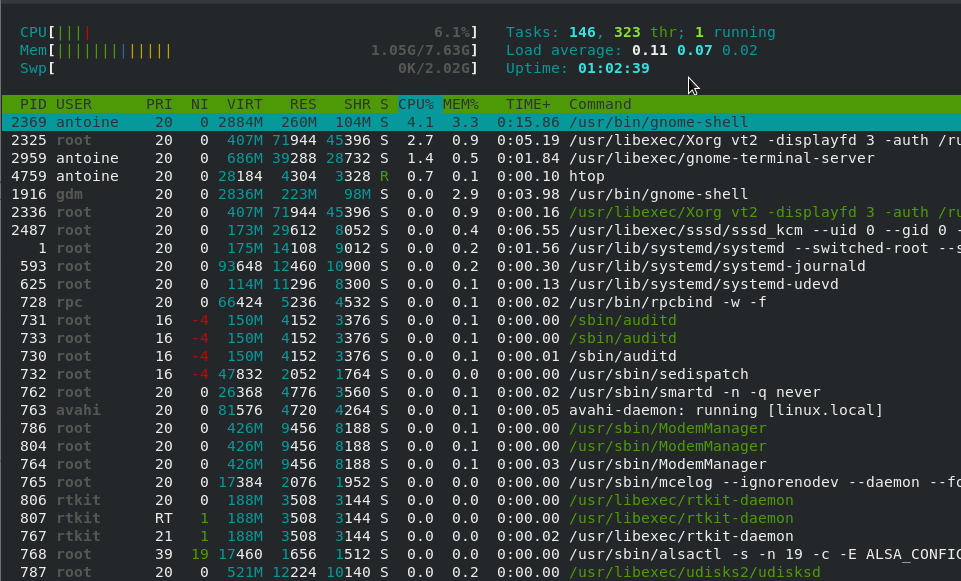
Mv is one of the Linux commands that must be learned. Mv stands for transferring files or directories from one place to another and is primarily used for moving them.
The syntax is similar to the cp command in Linux, but there is a fundamental distinction between these two commands.
The cp command can be called a copy-paste method. The mv instruction, while the cut-paste process can be equivalent.
This means the file or directory is transferred to a different location using the mv command on a file or directory. The source file/directory is no longer there.
- How to copy files from one location to another in a Routing Engine
- How to Rename Files and Directories in Linux
- How to Rename Directories in Linux
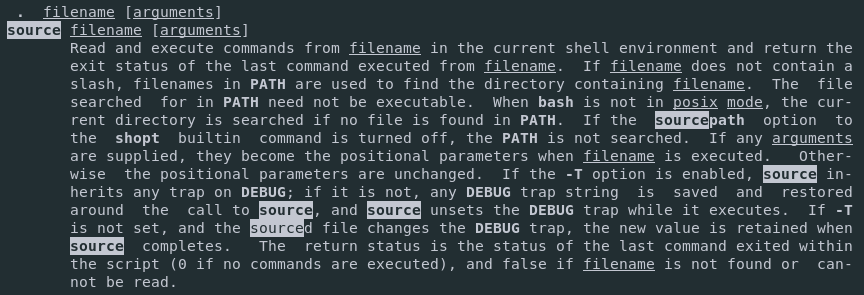
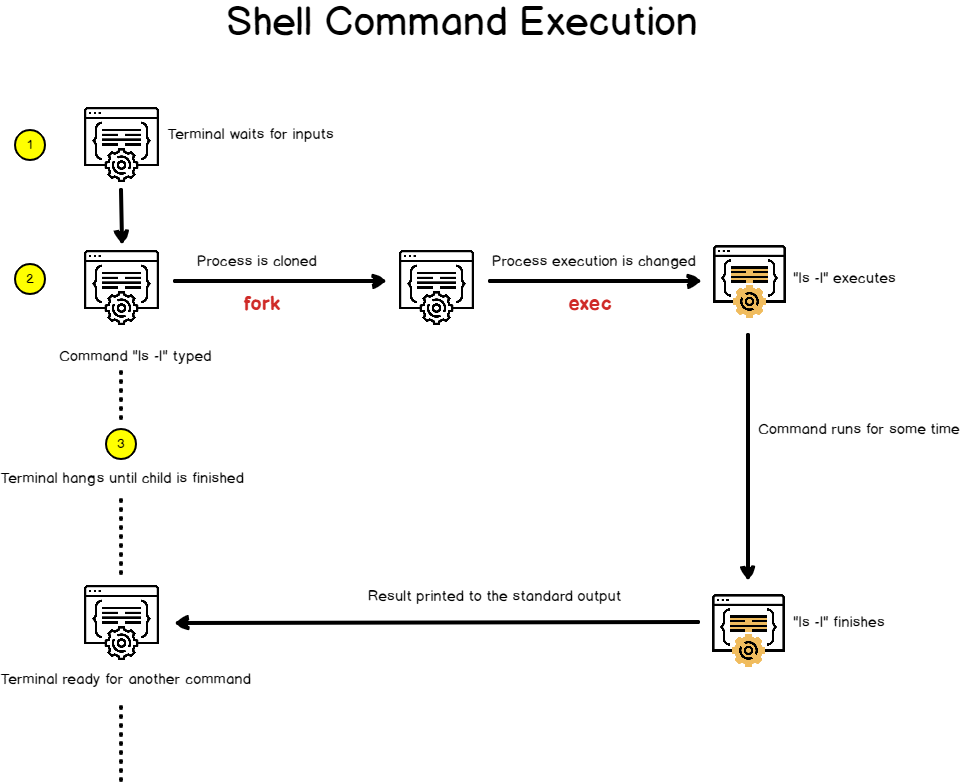
mv Command How can you use it?
The mv(transfer) command will move files and directories from place to place. It is also ideal for renaming files and folders.
mv [OPTIONS] source destination
- The source may be a single file or directory in the above command. The destination is always a single file or directory.
- When we have several files or folders, it is always a directory destination. Both source files and folders, in this case, are transferred to the directory of the destination. When we have a single source file and a destination directory, the file is transferred to the target folder.
- One crucial point is that when we transfer files and folders, we will obtain permission refused if we don’t have written permissions both for the source and destination.
mv mv image.png PNG
The current working directory transfers the image.png file to the PNG folder in the current work directory.
The original filename is renamed as the destination file if the destination directory isn’t present.
The image.png file is called PNG if it is not present in the existing working directory.
Transfer several folders and files
Specify the files you want to transfer as the source to move several files and folders. For instance, you would type to transfer file1 and file2 to the directory dir1:
mv File1 File2 dir1
You can also use pattern matching with the mv button. For, e.g., you would like to transfer all pdf files to the ~/Documents directory from the existing directory:
mv *.pdf ~/Documents
Drag a folder inside a separate folder with the mv command
We may use the following command to transfer a directory within another directory:
mv mv abcd abcd_New
It passes the abcd directory to another abcd New directory in our existing working directory.
The source directory is reset to the destination directory if the destination directory is not present.
How to transfer several files to another directory:
All source files and the path to the target directory are defined to transfer several files within a different directory.
mv <source(source)file path 3>
Our current working directory transfers the files 1.jpg, 2.jpg, and 2.png into a separate image directory in the current working directory.
Within a directory, we can transfer multiple files using regular expressions that match the filenames to be transferred.
Mv *jpg JPG
All files with mv backup:
We use the -b option to back up current files. It is intended to create a backup of the overwritten ~ character file with the attached backup file name.
mv -b a.jpg 1.jpg
ls
File rename
The mv command is essential for file renaming. The source file shall be renamed to the target file if you are using an mv command and specify a file name in your destination.
mv source_file target directory/target file
Suppose the target file does not exist in the target directory. In that case, the target file will be generated in the above case.
However, it overwrites without asking if the target file already exists. This means that with the source file’s content, the content of the current target file will be modified.
OverRight file when moving:
The existing file contents would be automatically overridden if a file is transferred and there is already a file with the same name.
In all cases, this might not be optimal. The overwriting scenario is available in a variety of ways.
You may use the -n option to avoid overwriting existing files. So mv will not overwrite the current file.
mv -n source_file target_directory
Forced movement of the file:
If you are shielded from writing the target file, you will be required to check until the target file is overwritten.
mv file1.txt target
Mv: substitute 'target/file1.txt' for 0444 overriding (r—r—r—) mode?
You may use the force option -f to bypass this prompt and overwrite the file immediately.
mv -f File1.txt target