As a system administrator, it is quite likely that you have written some Bash scripts in order to automate your work.
For example, you may want to run Bash scripts in order to backup your work or to log some events happening on your server.
Bash scripts, like scripts written in other programming languages, can be run in a wide variety of ways.
In this tutorial, we are going to focus on all the ways to run a Bash script on Linux.
Prerequisites
Before being able to run your script, you need your script to be executable.
In order to make a script executable on Linux, use the “chmod” command and assign “execute” permissions to the file.
You can either use the binary or the symbolic notation in order to make it executable.
$ chmod u+x script $ chmod 744 script
If you don’t own the file, you will have to make sure that you belong to the correct group or that permissions are given to the “other” group on your system.
Some distributions will highlight your file in a different color when your file is executable.

Now that your file is executable, let’s see how you can run your Bash script easily.
- Monitoring Linux Processes using Prometheus and Grafana | Prometheus & Grafana Linux Monitoring
- Cron Jobs and Crontab on Linux Explained | What is Cron Job & Crontab in Linux with Syntax?
- How To Install Docker on Ubuntu 18.04 & Debian 10
Run Bash Script from script path
In order to run a Bash script on Linux, simply specify the full path to the script and provide arguments that may needed in order to run your Bash script.
$ /path/to/script <arg1> <arg2> ... <argn>
As an example, let’s say that you have a Bash script located in your home directory.
In order to execute this script, you can specify the full path to the script that you want to run.
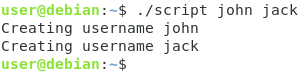
# Absolute path $ /home/user/script # Absolute path with arguments $ /home/user/script "john" "jack" "jim"
Alternatively, you can specify the relative path to the Bash script that you want to run.
# Relative path $ ./script # Relative path with arguments $ ./script "john" "jack" "jim"
Awesome, you learnt how you can easily run a Bash script on your system.
Run Bash Script using bash
In order to run a Bash script on your system, you have to use the “bash” command and specify the script name that you want to execute, with optional arguments.
$ bash <script>
Alternatively, you can use “sh” if your distribution has the sh utility installed.
As an example, let’s say that you want to run a Bash script named “script”.
In order to execute it using the “bash” utility, you would run the following command
$ bash script This is the output from your script!
Execute Bash script using sh, zsh, dash
Depending on your distribution, you may have other shell utilities installed on your system.
“Bash” is the shell interpreter installed by default, but you may want to execute your script using other interpreters.
In order to verify if a shell interpreter is installed on your system, use the “which” command and specify the interpreter you are looking for.
$ which sh /usr/bin/sh $ which dash /usr/bin/dash
Whenever you have identified the shell interpreter that you want to use, simply call it in order to run your script easily.
Run Bash script from anywhere
In some cases, you may want to run Bash scripts wherever you are on your system.
In order to run a Bash script from anywhere on your system, you need to add your script to your PATH environment variable.
$ export PATH="<path_to_script>:$PATH"
Now that the path to the script is added to PATH, you can call it from where you want on your system.
$ script This is the output from script!
Alternatively, you can modify the PATH environment variable in your .bashrc file and use the “source” command in order to refresh your current Bash environment.
$ sudo nano ~/.bashrc export PATH="<path_to_script>:$PATH"
Exit the file and source your bashrc file for the changes to be applied.
$ source ~/.bashrc $ echo $PATH /home/user/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games
Great! Now your script can be executed from where you want on your system.
Run Bash Scripts from the graphical interface
The last way to execute Bash scripts is to use the graphical interface, in this case the GNOME interface.
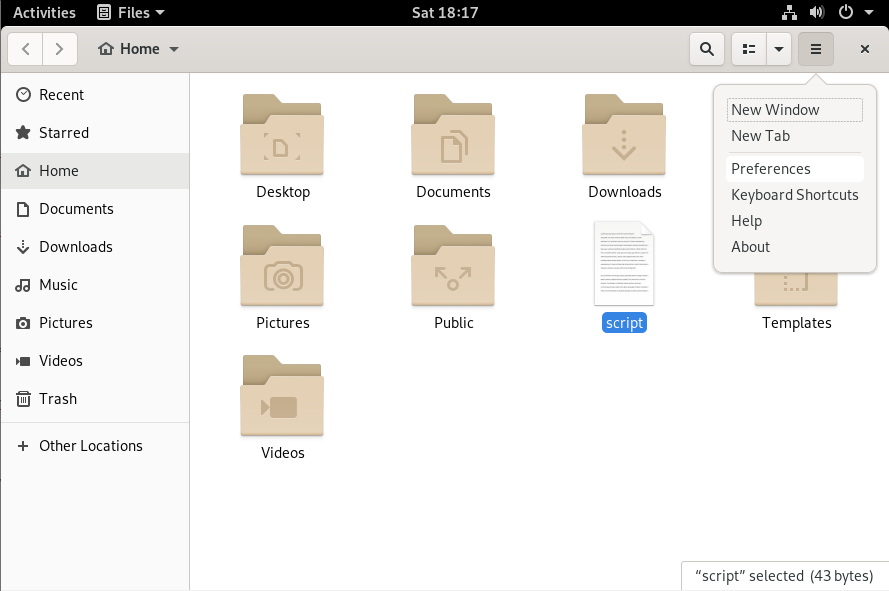
In order to run your scripts using GNOME, you have to set the behaviour of the File Explorer to “Ask what to do” for executable files.
To achieve that, in “Files“, click on the top right line icon and select “Preferences“.
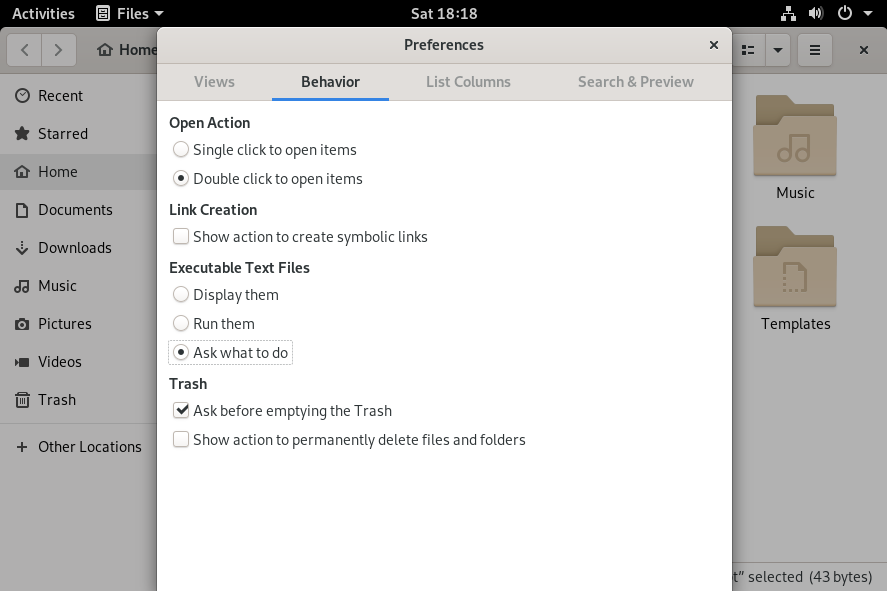
In the menu, click on “Behavior” and select “Ask what to do” under the “Executable Files” section.
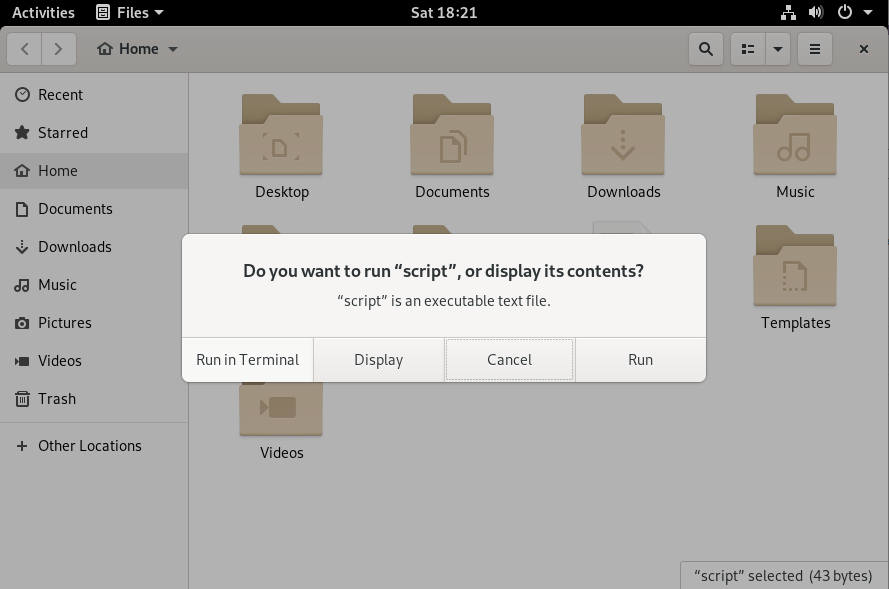
Close this window and double-click on the script file that you want to execute.
When double-clicking, you are prompted with various options : you can either choose to run your script (in a terminal or not) or to simply display the content of the file.
In this case, we are interested in running this script in the terminal, so click on this option.
Success! Your script has been successfully executed within a new shell instance.
Conclusion
In this tutorial, you learnt how you can easily run Bash scripts on your system, either by specifying the path to the script or the interpreters available on your host.
You learnt that you can make it even easier by adding your script path to your PATH environment variable or using existing features in the GNOME user interface.
If you are interested in Bash or Linux system administration, we have a complete section dedicated to it on the website, so make sure to check it out!