In today’s tutorial, we are going to see how you can add a user to sudoers on Debian distributions.
The sudo command allows authorized users to perform commands as another user, which is by default the root user.
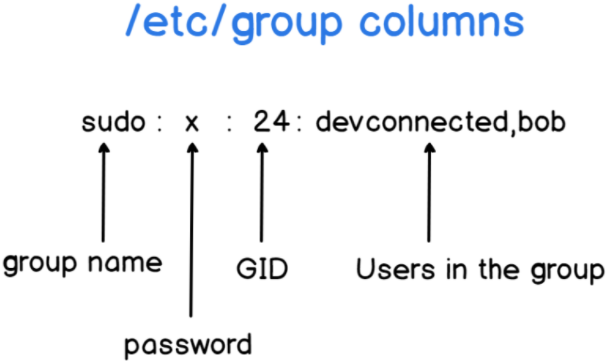
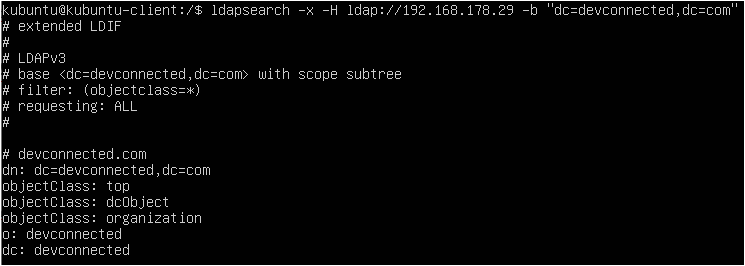
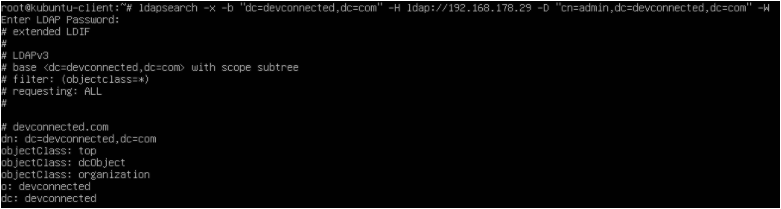
There are two ways to add a user to sudoers : you can add this user to the sudo group or you can add this user to the sudoers file located at etc.
Here are the details of the two methods.
I – Adding an existing user to the sudo group
As a prerequisites, make sure that the sudo command is available by default. If it’s not the case, you can install it by running (with an account with admin rights)
$ apt-get update $ apt-get install sudo
The first method is to add the user to the sudo group.
To do that, you are going to use the “usermod” command with the capital G flag (for groups)
$ sudo usermod -a -G sudo user
You can also use the gpasswd command to grand sudo rights.
$ sudo gpasswd -a bob sudo Adding user to the group sudo
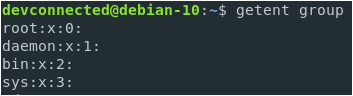
Make sure that the user belongs to the sudo group with the groups command.
$ su - user (password for user) $ groups user sudo
- How To Add A User to Sudoers On CentOS 8 | Centos 8 Add User to Group
- How To Install Docker on Ubuntu 18.04 & Debian 10
- How To Install InfluxDB 1.7 and 2.0 on Linux in 2021
You should now be able to perform a sudo request on Debian 10.
Depending on the configuration you chose during your Debian 10 installation process, you may or may not have access to a root account. If you chose a password for your root account, you will be able to connect to it. Otherwise, the default admin account is the one you created during the installation process.
The sudoers file is located at /etc/sudoers.
This file contains a set of rules that are applied to determine who has sudo rights on a system, which commands they can execute with sudo privileges, and if they should be prompted a password or not.
However, you should never modify the sudoers file with a text editor.
Saving a bad sudoers may leave you with the impossibility of getting sudo rights ever again.
Instead, you are going to use visudo, a tool designed to make sure you don’t do any mistakes.
$ sudo visudo
This is what you should see.
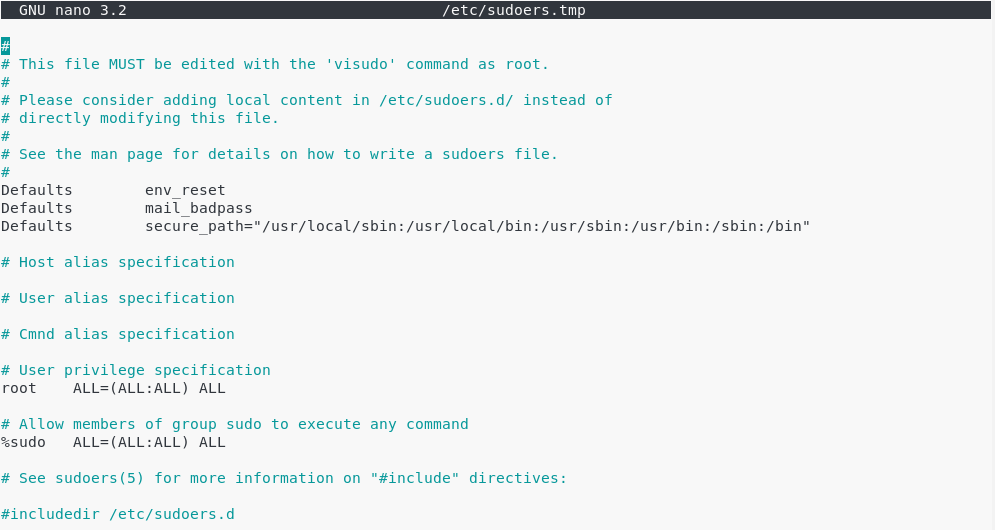
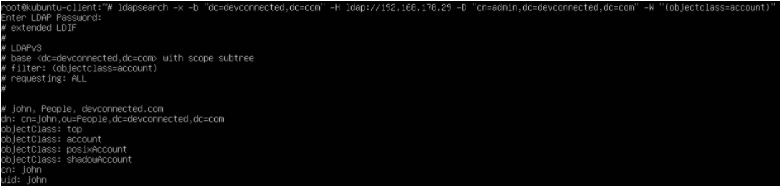
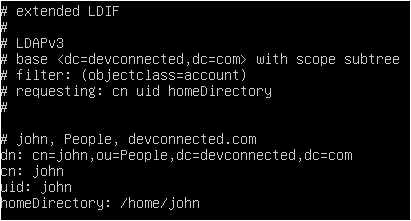
At the end of the file, add a new line for the user.
john ALL=(ALL:ALL) ALL
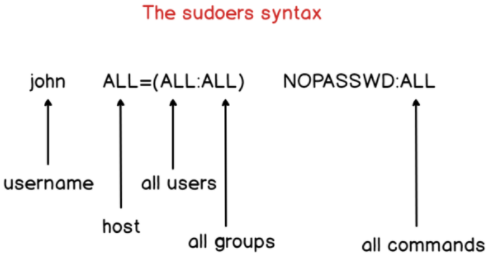
By default, the account password will be asked every five minutes to perform sudo operations.
However, if you want to remove this password verification, you can set the NOPASSWD option.
john ALL=(ALL:ALL) NOPASSWD:ALL
If you want the password verification to be skipped for longer periods of time, you can overwrite the timestamp_timeout (in minutes) parameter in your sudoers file.
# /etc/sudoers # # This file MUST be edited with the 'visudo' command as root. # # See the man page for details on how to write a sudoers file. # Defaults env_reset Defaults mail_badpass Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin Defaults timestamp_timeout=30
III – Adding a group to the sudoers file
Via the visudo, you can add an entire group to the sudoers.
This might be handy if you have a group for system administrators for example. In this case, you simply have to add a user to the system administrators group for him/her to be granted sudo privileges.
To add a group to the sudoers file, simply add a percent symbol at the beginning of the file.
%sysadmins ALL=(ALL:ALL) NOPASSWD:ALL
Make sure that your user is part of the designed group with the groups command.
$ su - user $ groups user sysadmins
You can test your new sudo rights by changing your password for example
$ sudo passwd
IV – Most Common Errors
- user is not in the sudoers file. This incident will be reported.
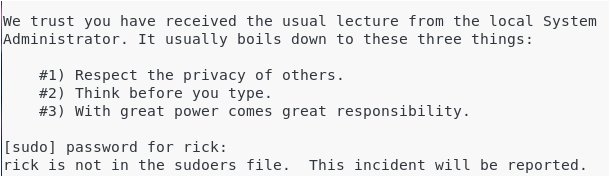
This is the standard error message you get when a user does not belong to the sudo group on Debian 10.
By adding this user to the sudoers file on Debian, this error message should not be raised anymore.