Copying directories on Linux is a big part of every system administrator routine.
If you have been working with Linux for quite some time, you know how important it is to keep your folders well structured.
In some cases, you may need to copy some directories on your system in order revamp your main filesystem structure.
In this tutorial, we are going to see how you can easily copy directories and folders on Linux using the cp command.
Copy Directories on Linux
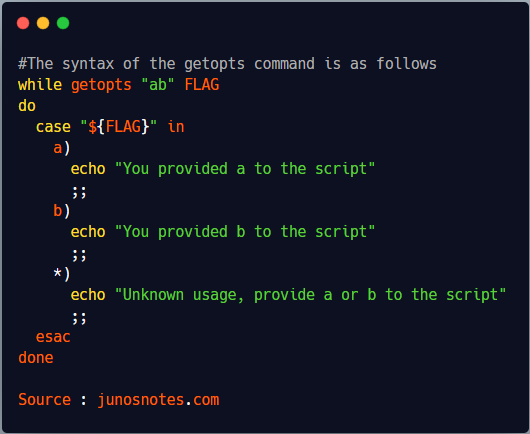
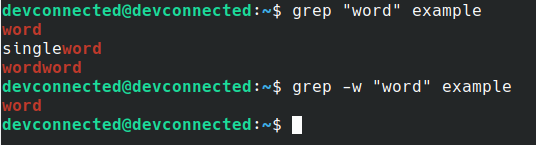
In order to copy a directory on Linux, you have to execute the “cp” command with the “-R” option for recursive and specify the source and destination directories to be copied.
$ cp -R <source_folder> <destination_folder>
As an example, let’s say that you want to copy the “/etc” directory into a backup folder named “/etc_backup”.
The “/etc_backup” folder is also located at the root of your filesystem.
In order to copy the “/etc” directory to this backup folder, you would run the following command
$ cp -R /etc /etc_backup
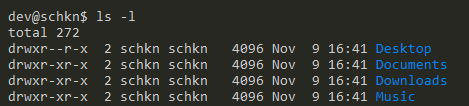
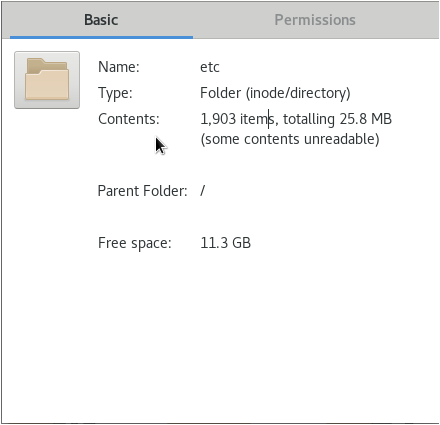
By executing this command, the “/etc” folder will be copied in the “/etc_backup”, resulting in the following folder.

Awesome, you successfully copied one folder in another folder on Linux.
But, what if you wanted to copy the content of the directory, recursively, using the cp command?
Copy Directory Content Recursively on Linux
In order to copy the content of a directory recursively, you have to use the “cp” command with the “-R” option and specify the source directory followed by a wildcard character.
$ cp -R <source_folder>/* <destination_folder>
Given our previous example, let’s say that we want to copy the content of the “/etc” directory in the “/etc_backup” folder.
In order to achieve that, we would write the following command
$ cp -R /etc/* /etc_backup
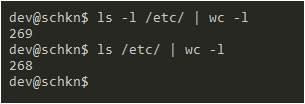
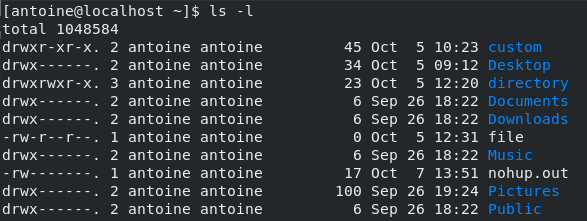
When listing the content of the backup folder, you will come to realize that the folder itself was not copied but the content of it was.
$ ls -l /etc_backup
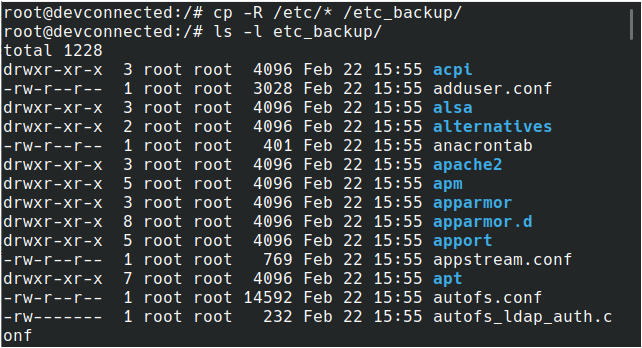
Awesome, you copied the content of the “/etc” directory right into a backup folder!
- Cron Jobs and Crontab on Linux Explained | What is Cron Job & Crontab in Linux with Syntax?
- How to Move Files and Directories in Linux with mv Command
- Access Control Lists on Linux Explained | Linux ACL Cheat Sheet
Copy multiple directories with cp
In order to copy multiple directories on Linux, you have to use the “cp” command and list the different directories to be copied as well as the destination folder.
$ cp -R <source_folder_1> <source_folder_2> ... <source_folder_n> <destination_folder>
As an example, let’s say that we want to copy the “/etc” directory as well as all homes directories located in the “/home” directory.
In order to achieve that, we would run the following command
$ cp -R /etc/* /home/* /backup_folder
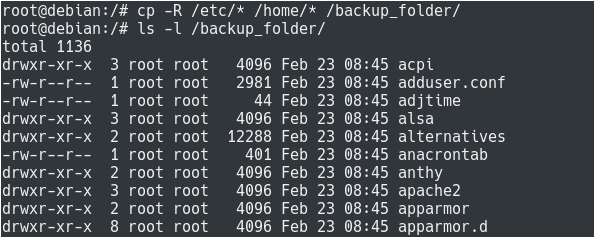
Congratulations, you successfully copied multiple directories using the cp command on Linux!
Copy Directories To Remote Hosts
In some cases, you may want to copy a directory in order to keep a backup on a backup server.
Needless to say that your backup server is locally remotely : you have to copy your directory over the network.
Copying using rsync
In order to copy directories to remote locations, you have to use the rsync command, specify the source folder as well as the remote destination to be copied to.
Make sure to include the “-r” option for “recursive” and the “-a” option for “all” (otherwise non-regular files will be skipped)
$ rsync -ar <source_folder> <destination_user>@<destination_host>:<path>
Also, if the “rsync” utility is not installed on your server, make sure to install it using sudo privileges.
$ sudo apt-get install rsync $ sudo yum install rsync
As an example, let’s say that we need to copy the “/etc” folder to a backup server located at 192.168.178.35/24.
We want to copy the directory to the “/etc_backup” of the remote server, with the “devconnected” username.
In order to achieve that, we would run the following command
$ rsync -ar /etc devconnected@192.168.178.35:/etc_backup

Note : we already wrote a guide on transferring files and folders over the network, if you need an extensive guide about it.
Similarly, you can choose to copy the content of the “/etc/ directory rather than the directory itself by appending a wildcard character after the directory to be copied.
$ rsync -ar /etc/* devconnected@192.168.178.35:/etc_backup/
Finally, if you want to introduce the current date while performing a directory backup, you can utilize Bash parameter substitution.
$ rsync -ar /etc/* devconnected@192.168.178.35:/etc_backup/etc_$(date "+%F")
Note : if you are looking for a tutorial on setting dates on Linux, we have a guide about it on the website.
Copying using scp
In order to copy directory on Linux to remote location, you can execute the “scp” command with the “-r” option for recursive followed by the directory to be copied and the destination folder.
$ scp -r <source_folder> <destination_user>@<destination_host>:<path>
As an example, let’s say that we want to copy the “/etc” directory to a backup server located at 192.168.178.35 in the “/etc_backup” folder.
In order to achieve that, you would run the following command
$ scp -r /etc devconnected@192.168.178.35:/etc_backup/
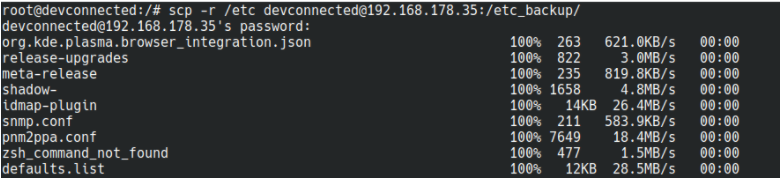
Congratulations, you successfully copied an entire directory using the scp command.
Very similarly to the rsync command, you can choose to use Bash parameter substitution to copy your directory to a custom directory on your server.
$ scp -r /etc devconnected@192.168.178.35:/etc_backup/etc_$(date "+%F")
Conclusion
In this tutorial, you learnt how you can easily copy directories on Linux, whether you choose to do it locally or remotely.
Most of the time, copying directories is done in order to have backups of critical folders on your system : namely /etc, /home or Linux logs.
If you are interested in Linux System Administration, we have a complete section dedicated to it on the website, so make sure to check it out!