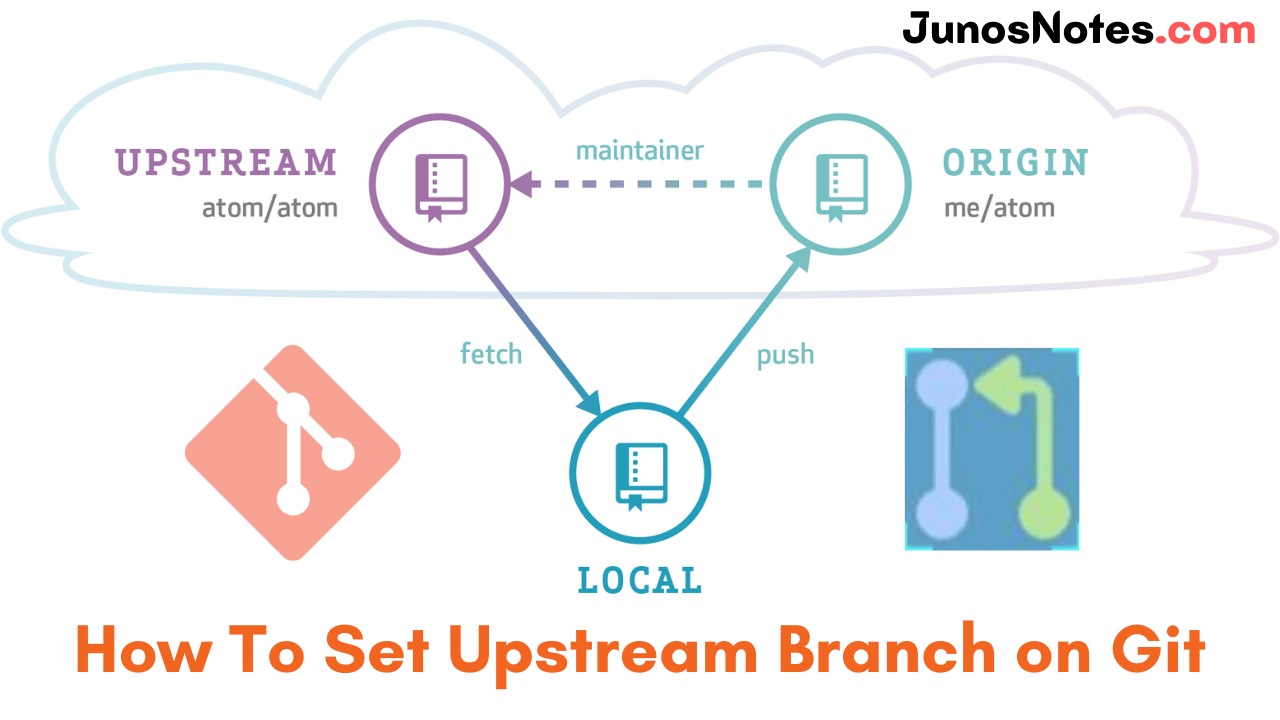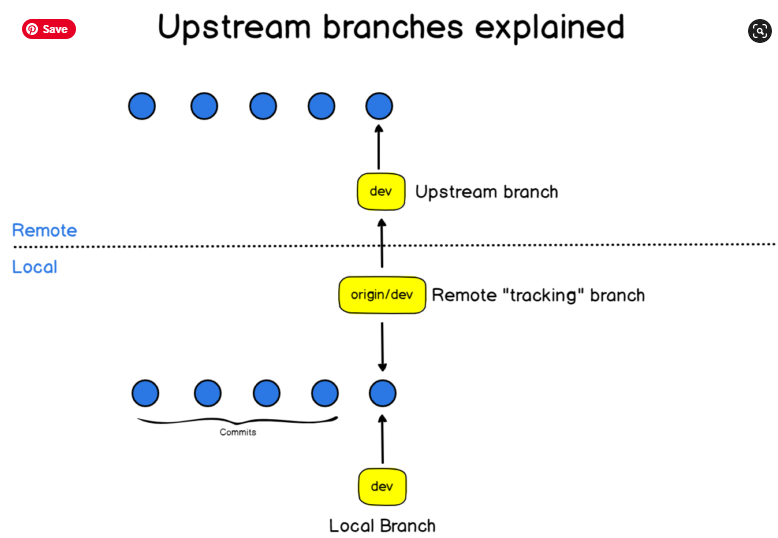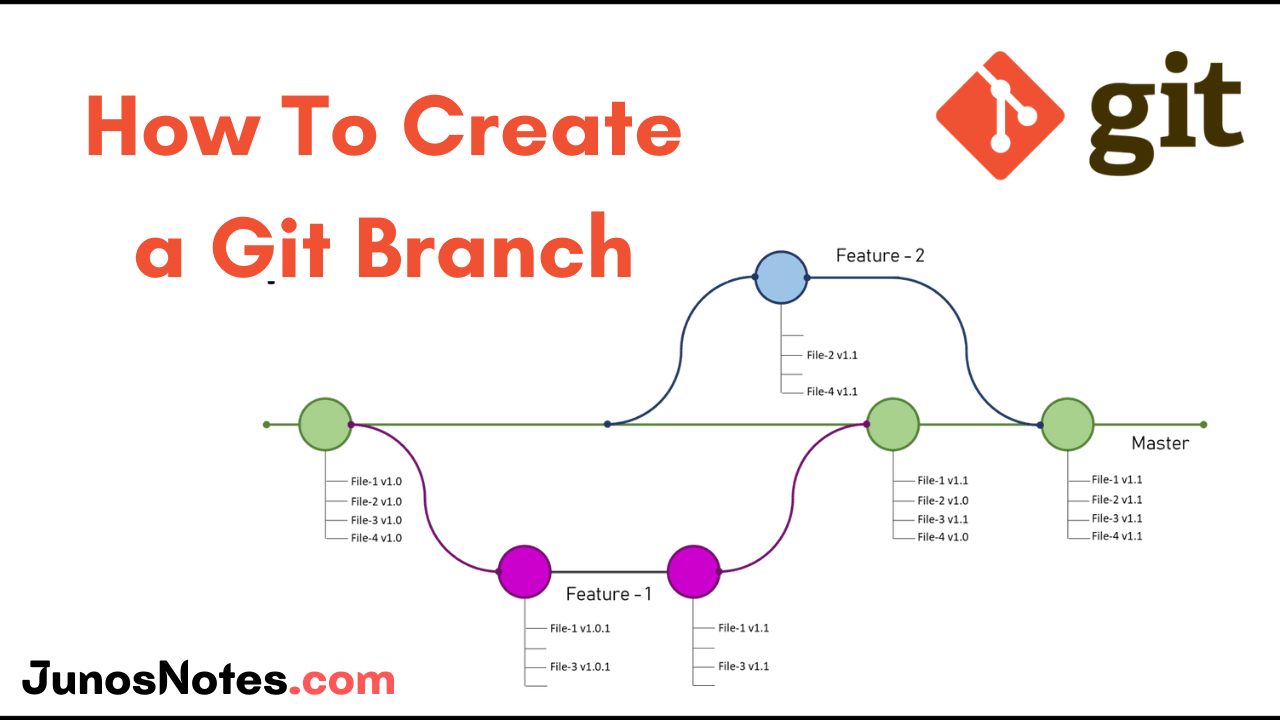
If you are developing a large project then you need to be familiar with this important concept called Git submodules. Git submodules permit you to have a git repository as a subdirectory of different git repositories. Just these are a reference to another repository at a particular snapshot in time.
Do Check: GIT Commands
Also, Git submodules allow a Git repository to incorporate another versioned project within an existing project and track the version history of external code. In this tutorial, we are discussing how easily add, update and remove Git submodules on your main project can be done. Apart from this, we will describe concepts about Git submodules
- What is a Submodule?
- When should you use a git submodule?
- Add a Git Submodule
- Pull a Git Submodule
- Steps on how to Update Git Submodules
- Update a Git Submodule
- Git Submodules Update Example
- Fetch new submodule commits
- Remove Git submodules
- Configuring submodules for your repository
- Submodule summary
- Detailed diff for submodules
What is a Submodule?
A Submodule is a Git Repository inside another Git Repository. This embedded Git Repository can be run separately and will have its individual Git workflow. This embedded repository can also be used as a Submodule for various other repositories without generating new files from scratch for each repository.
When should you use a git submodule?
By using the Git submodules, you can easily maintain strict version management over your external dependencies. The furnished points are some of the best use cases for git submodules:
- When you have a component that isn’t updated very often and you want to track it as a vendor dependency.
- When an external component or subproject is changing too fast or upcoming changes will break the API, you can lock the code to a specific commit for your own safety.
- When you are delegating a piece of the project to a third party and you want to integrate their work at a specific time or release. Again this works when updates are not too frequent.
Do Refer: How To Create and Apply Git Patch Files
Add a Git Submodule
The first thing you want to do is to add a Git submodule to your main project.
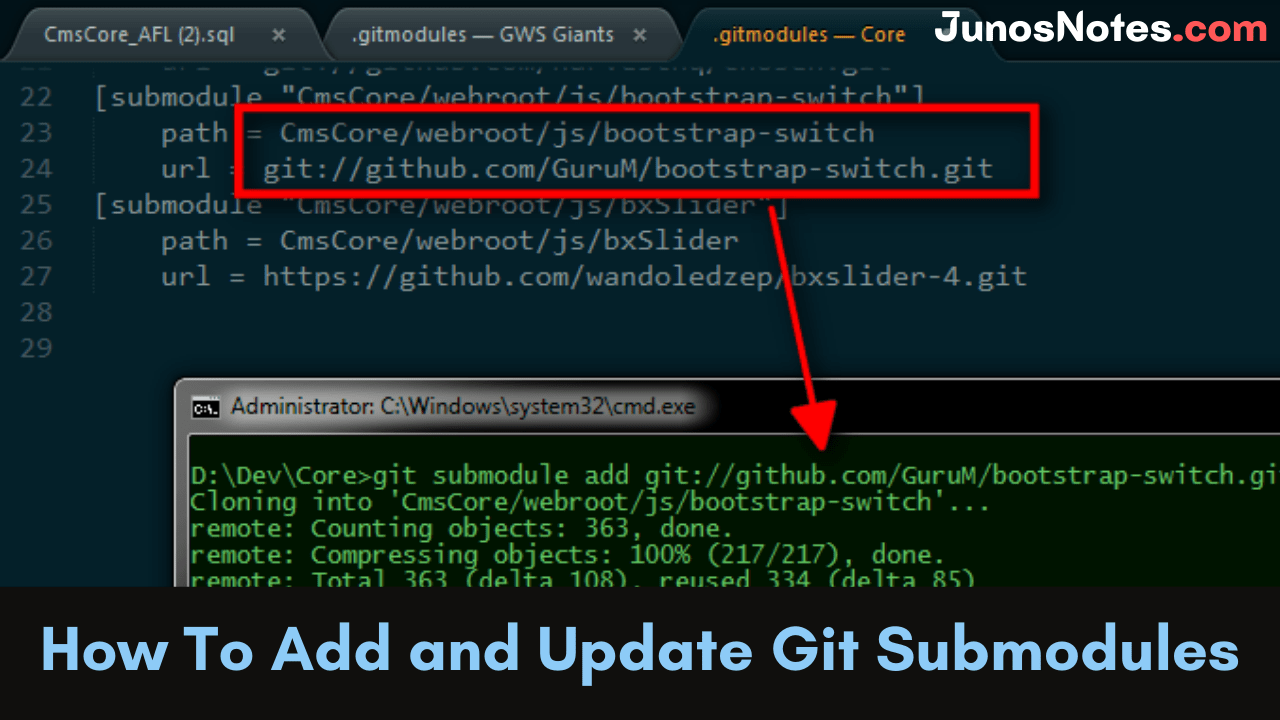
In order to add a Git submodule, use the “git submodule add” command and specify the URL of the Git remote repository to be included as a submodule.
Optionally, you can also specify the target directory (it will be included in a directory named like the remote repository name if not provided)
$ git submodule add <remote_url> <destination_folder>
When adding a Git submodule, your submodule will be staged. As a consequence, you will need to commit your submodule by using the “git commit” command.
$ git commit -m "Added the submodule to the project." $ git push
As an example, let’s pretend that you want to add the “project” repository as a submodule on your project into a folder named “vendors”.
- How To Git Add All Files | Git How to Add All Modified File to Commit?
- How To Create a Git Branch | Learn Git Create New Branch from Current Branch
- How To Change Git Remote Origin | What is Git Remote? | Git Remote Add Origin
To add “project” as a submodule, you would run the following command at the root of your repository
$ git submodule add https://github.com/project/project.git vendors Cloning into '/home/user/main/project'... remote: Enumerating objects: 5257, done. remote: Total 5257 (delta 0), reused 0 (delta 0), pack-reused 5257 Receiving objects: 100% (5257/5257), 3.03 MiB | 3.38 MiB/s, done. Resolving deltas: 100% (3319/3319), done.
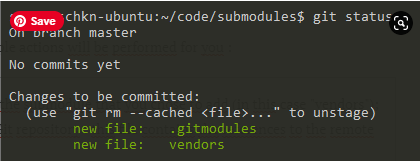
When adding a new Git submodule into your project, multiple actions will be performed for you:
- A folder is created in your Git repository named after the submodule that you chose to add (in this case “vendors”);
- A hidden file named “.gitmodules” is created in your Git repository: this file contains the references to the remote repositories that you cloned as submodules;
- Your Git configuration (located at .git/config) was also modified in order to include the submodule you just added;
- The submodule you just added is marked as a change to be committed in your repository.
Pull a Git Submodule
In this section, we are going to see how you can pull a Git submodule as another developer on the project.
Whenever you are cloning a Git repository having submodules, you need to execute an extra command in order for the submodules to be pulled.
If you don’t execute this command, you will fetch the submodule folder, but you won’t have any content in it.
To pull a Git submodule, use the “git submodule update” command with the “–init” and the “–recursive” options.
$ git submodule update --init --recursive
Going back to the example we described before: let’s pretend that we are in a complete new Git repository created by our colleague.
In its Git repository, our colleague first starts by cloning the repository, however, it is not cloning the content of the Git submodule.
To update its own Git configuration, it has to execute the “git submodule update” command.
$ git submodule update --init --recursive Submodule 'vendors' (https://github.com/project/project.git) registered for path 'vendors' Cloning into '/home/colleague/submodules/vendors'... Submodule path 'vendors': checked out '43d08138766b3592352c9d4cbeea9c9948537359'
As you can see, pulling a Git submodule in our colleague Git repository detached the HEAD at a given commit.
The submodule is always set to have its HEAD detached at a given commit by default: as the main repository is not tracking the changes of the submodule, it is only seen as a specific commit from the submodule repository.
Steps on how to Update Git Submodules
For updating the Git submodules in your workspace with the latest commits on the server please follow the below steps carefully:
- Clone the remote repository, if you haven’t already.
- Issue a git submodule update –remote command.
- Add any new files pulled from the repository to the Git index.
- Perform a git commit.
- Push back to origin.
Update a Git Submodule
In some cases, you are not pulling a Git submodule but you are simply looking to update your existing Git submodule in the project.
In order to update an existing Git submodule, you need to execute the “git submodule update” with the “–remote” and the “–merge” option.
$ git submodule update --remote --merge
Using the “–remote” command, you will be able to update your existing Git submodules without having to run “git pull” commands in each submodule of your project.
When using this command, your detached HEAD will be updated to the newest commit in the submodule repository.
Given the example that we used before when updating the submodule, we would get the following output:
$ git submodule update --remote --merge Updating 43d0813..93360a2 Fast-forward README.md | 6 +++++- 1 file changed, 5 insertions(+), 1 deletion(-) Submodule path 'vendors': merged in '93360a21dc79011ff632b68741ac0b9811b60526'
Git Submodules Update Example
For executing the update git submodules example on your local machine, you can make use of the following commands:
submodule@example:~$ git clone --recurse-submodules https://gitlab.com/cameronmcnz/surface.git submodule@example:~$ cd sur* submodule@example:~$ git submodule update --remote submodule@example:~$ git add . submodule@example:~$ git commit -m "git submodule updated" submodule@example:~$ git push origin
Fetch new submodule commits
In this section, you are looking to update your Git repository with your commits coming from the submodule repository.
First, you may want to fetch new commits that were done in the submodule repository.
Let’s say for example that you want to fetch two new commits that were added to the submodule repository.
To fetch new commits done in the submodule repository, head into your submodule folder and run the “git fetch” command first (you will get the new submodule commits)
$ cd repository/submodule $ git fetch
Now, if you run the “git log” command again, you will be able to see the new commits you are looking to integrate.
$ git log --oneline origin/master -3 93360a2 (origin/master, origin/HEAD) Second commit 88db523 First commit 43d0813 (HEAD -> master) Initial commit
Now, in order for your submodule to be in line with the newest commits, you can run the “git checkout” command and specify the SHA that you want to update your submodule to (in this case 93360a2)
$ git checkout -q 93360a2
Great! Your HEAD is now aligned with the newest commits from the submodule repository.
You can now go back to your main repository and commit your changes for other developers to fetch those new commits.
$ cd repository $ git add. $ git commit -m "Added new commits from the submodule repository" $ git push
Remove Git submodules
In this section, we are going to see how you can effectively remove a Git submodule from your repository.
In order to remove a Git submodule from your repository, use the “git submodule deinit” command followed by the “git rm” command and specify the name of the submodule folder.
$ git submodule deinit <submodule> $ git rm <submodule>
When executing the “git submodule deinit” command, you will delete the local submodule configuration stored in your repository.
As a consequence, the line referencing the submodule will be deleted from your .git/config file.
The “git rm” command is used in order to delete submodules files from the working directory and remaining .git folders.
Configuring submodules for your repository
In some cases, you may want to have additional logging lines whenever you are executing “git status” commands.
Luckily for you, there are configuration properties that you can tweak in order to have more information about your submodules.
Submodule summary
In order to have a submodule summary when executing “git status”, execute the “git config” command and add the “status.submoduleSummary” option.
$ git config --global status.submoduleSummary true
As a consequence, you will be presented with more information when executing “git status” commands.
$ git status On branch master Your branch is up-to-date with 'origin/master'. Changes to be committed: (use "git reset HEAD <file>..." to unstage) new file: .gitmodules new file: <submodule> Submodule changes to be committed: * <submodule> 0000000...ae14a2 (1): > Change submodule name
Detailed diff for submodules
If you configured your Git to have the submodule summary as explained in the previous section, you should now have a customized way to see the differences between submodules.
However, in some cases, you want to get more information about the commits that might have been done in your submodules folder.
For the “git diff” command to have detailed information about your submodules, use the “git config” command with the “diff.submodule” parameter set to true.
$ git config --global diff.submodule log
Now, whenever you are executing the “git diff” command, you will be able to see the commits that were done in the submodules folder.
$ git diff Submodule <submodule> 0000000...ae14a2: > Submodule commit n°1 > Submodule commit n°2
Conclusion
In this tutorial, you learned what submodules are and how you can use them in order to have external repositories in your main project repository. Also, more about how to add and update Git submodules using the dedicated “git submodule” commands: “git submodule add” and “git submodule update“.
Finally, you have seen that it is possible to tweak your Git configuration in order to get more information about your Git repository.